
时序异常检测系统 EGADS
egads是雅虎开源的可扩展异常检测系统, 地址:https://github.com/yahoo/egads
tsmm模型
DoubleExponentialSmoothingModel
双指数平滑 - 也称为Holt指数平滑 - 改进了常见的简单指数平滑模型,考虑了数据中含有有趋势因素的情况。
MovingAverageModel
移动平均预测模型基于人工构建的时间序列,其中给定时间段的值由该值的平均值和某些前后时间段的值代替。
MultipleLinearRegressionModel
多变量线性回归模型
NaiveForecastingModel
朴素预测模型是移动平均预测模型的一个特例,即当 平滑周期数为1时的特例。
OlympicModel
去掉一个最高分,去掉一个最低分,然后计算最近k周的数据的平均数,作为当前的预测值。
PolynomialRegressionModel
单变量多项式回归模型
RegressionModel
单变量线性回归模型
SimpleExponentialSmoothingModel
简单指数平滑回归模型
SpectralSmoother
基于输入时间序列’Hankel矩阵的奇异值分解(SVD)实现平滑技术
TripleExponentialSmoothingModel
三指数平滑,也称为Winters方法, 是双指数平滑模型的改进,考虑了数据中含有季节性和周期性
WeightedMovingAverageModel
加权移动平均模型,由当前周期和上个周期的数据做的加权平均值做为当前的预测值
adm模型
AdaptiveKernelDensityChangePointDetector
基于核密度的变点检测
https://blog.csdn.net/gdp12315_gu/article/details/49766245DBScanModel
评价指标
时序的几种特征
Periodicity (frequency)
Periodicity is very important for determining the seasonality.
Trend
Exists if there is a long-term change in the mean level Seasonality Exists when a time series is influenced by seasonal factors, such as month of the year or day of the week
- Auto-correlation
Represents long-range dependence.
- Non-linearity
A non-linear time-series contains complex dynamics that are usually not represented by linear models.
- Skewness
Measures symmetry, or more precisely, the lack of symmetry.
- Kurtosis
Measures if the data are peaked or flat, relative to a normal distribution.
- Hurst
A measure of long-term memory of time series.
- Lyapunov Exponent
A measure of the rate of divergence of nearby trajectories.
如何选择模型
基于时序数据的特征来选择模型,比将时序数据在各个模型上交叉测试要快的多。 by:6.2.1
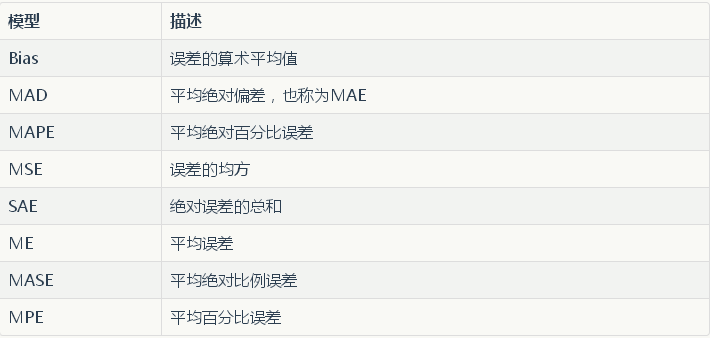
当时序是强趋势性特征时,各个模型的表现
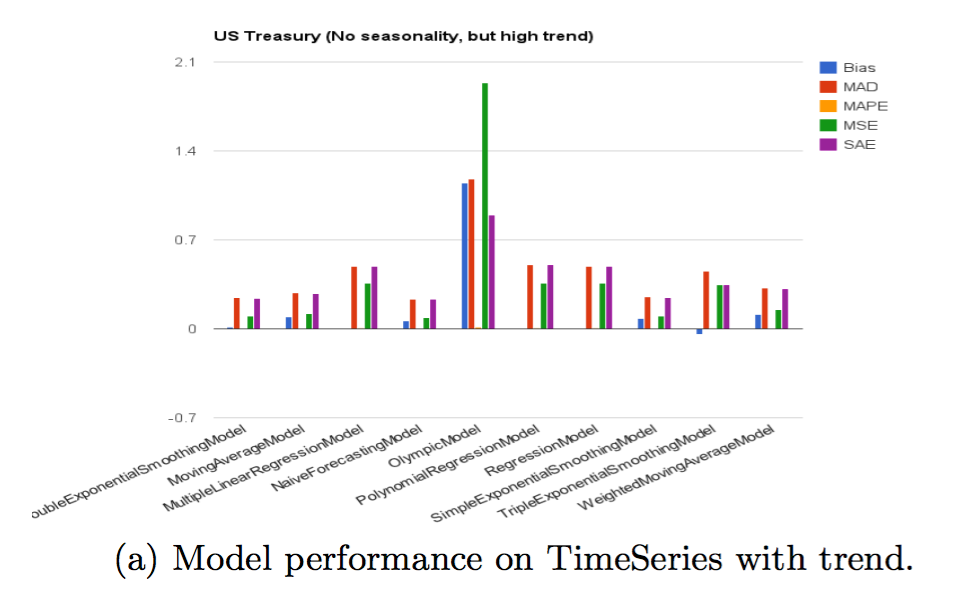
当时序是强趋势性+强季节性特征时,各个模型的表现
如何评价异常检测模型
召回率和准确率的定义
一个数据库有500个文档,其中有50个文档符合定义。系统检索到75个文档,但是实际其中只有45个符合定义。则:
召回率R=45/50=90%
准确率P=45/75=60%
一个评价异常检测adm算法的指标
$$F-Score = \frac{precision * recall}{precision + recall}$$
F-Score越大,则检测的效果越好。
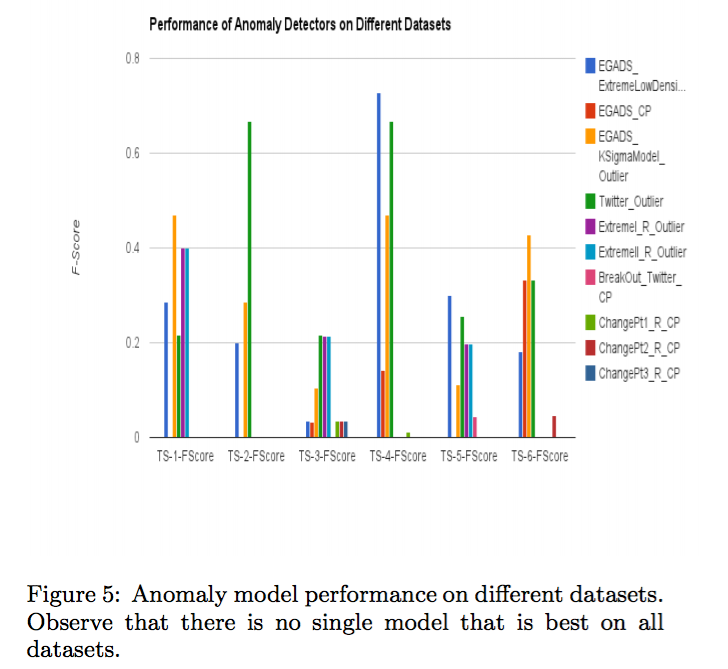
该图展示了EGADS中CP(不知道是啥,论文里没写), extremeLowDensity和KSigmaModel这三种adm模型,但其实谁也没比谁好。
过滤
将各种模型跑出来的所有的异常点,(所有模型太多了,挑4个左右吧)。
WeightedMovingAverageModel是在8个tsmm模型里比较出来,对我们业务数据来说12小时长的时序数据,是拟合最好的模型。经过6个adm模型的运行对比,DBScanModel, ExtremeLowDensityModel, kSigma这三个模型较为灵敏,能够检测出绝大多数异常, 准确率各不相同。
- DBScan, LowDensity和 kSigma 召回率较高
- kSigma 准确率低,有误检
- kerneldensity, Naive,Simple召回率低
利用adaboost算法来识别出真正的异常点
收集训练集,
样本为:((业务数据类型, 进一个小时监控数据), 标记-1或1)
设计弱分类器:
- 按业务数据类型分类
- 按近一小时数据的均值 > n
按近一小时数据的均值 > m
…
- 近10分钟数据方差 > x
近10分钟数据方差 > y
…
要有一个库,已标记,和未标记
- 可以根据业务数据类型,批量标记
- 可以选择不标记指定的业务数据类型
如何自己实现adaboost
1
2
https://www.ibm.com/developerworks/cn/analytics/library/machine-learning-hands-on6-adaboost/index.html
用标准差跟均值的距离来判断 (目前线上使用的是类似这种方法)
其中有几种tsmm的解释
https://jiroujuan.wordpress.com/